What is Spring Data JPA?
Spring Data JPA is a module of Spring Data that simplifies the implementation of repositories. It provides an automatic way to create repository implementations based on Java interfaces, eliminating the need to manually write the repository implementation.
To make this work, you need to create an interface using the @Repository annotation and extend JpaRepository. The ORM entity must be properly mapped using the necessary annotations, such as @Entity and others. At runtime, an implementation will be generated with several methods — for example, findAll, which returns a list of all items found in the database. You can also create custom methods.
Let’s go through it step by step.
Hands on
To get started, you need to import Spring Data JPA and the database connector.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>In the application.properties file, we specify the database connection settings.
spring.datasource.url=jdbc:mysql://localhost/nutri_dev?createDatabaseIfNotExist=true&serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=After that, define the entity. I’m using Lombok to keep the code cleaner.
import jakarta.persistence.*;
import lombok.Data;
import lombok.EqualsAndHashCode;
@Entity
@Data
@EqualsAndHashCode(onlyExplicitlyIncluded = true)
public class Food {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@EqualsAndHashCode.Include
private Long id;
private String name;
private Integer quantity;
@Enumerated(EnumType.STRING)
private Unity unity;
private Integer kcal;
private Double fat;
private Double carb;
private Double protein;
private Double sodium;
private Double fiber;
@Enumerated(EnumType.STRING)
private Origin origin;
}
Here is the enum used by the entity.
public enum Origin {
ANIMAL,
VEGETABLE
}public enum Unity {
G,
ML
}Now it’s time to create the Repository interface.

import com.natancode.nutri.domain.model.Food;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface FoodRepository extends JpaRepository<Food, Long> {
}This interface defines a Spring Data JPA repository for the Food entity. With this setup, Spring automatically generates all the necessary implementation to perform database operations such as save, findAll, delete, etc.
public interface FoodRepository extends JpaRepository<Food, Long>
Here, we are declaring that FoodRepository is a data repository for the Food entity, whose primary key is of type Long.
By extending JpaRepository, we automatically inherit methods such as:
findById(Long id)findAll()save(Food food)deleteById(Long id)- and others!
@Repository
This annotation marks the interface as a Spring component from the repository layer. Although optional when extending JpaRepository, it helps with exception handling.
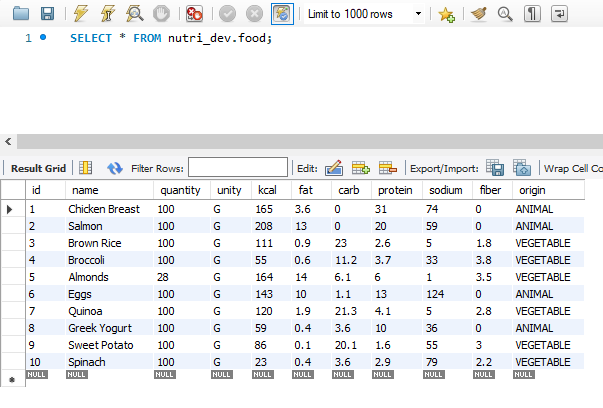
Now let’s retrieve all items — the table is already populated.
I’ll create a Service to use the Repository.
package com.natancode.nutri.domain.services;
import com.natancode.nutri.domain.model.Food;
import com.natancode.nutri.domain.repository.FoodRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class FoodService {
@Autowired
private FoodRepository foodRepository;
public List<Food> findAll() {
return foodRepository.findAll();
}
}
Next, I’ll create an Endpoint to return the list of Food.
package com.natancode.nutri.api;
import com.natancode.nutri.domain.services.FoodService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping(path = "/v1/foods")
public class FoodController {
@Autowired
private FoodService foodService;
@GetMapping
public ResponseEntity<?> findAll() {
return ResponseEntity.ok(foodService.findAll());
}
}
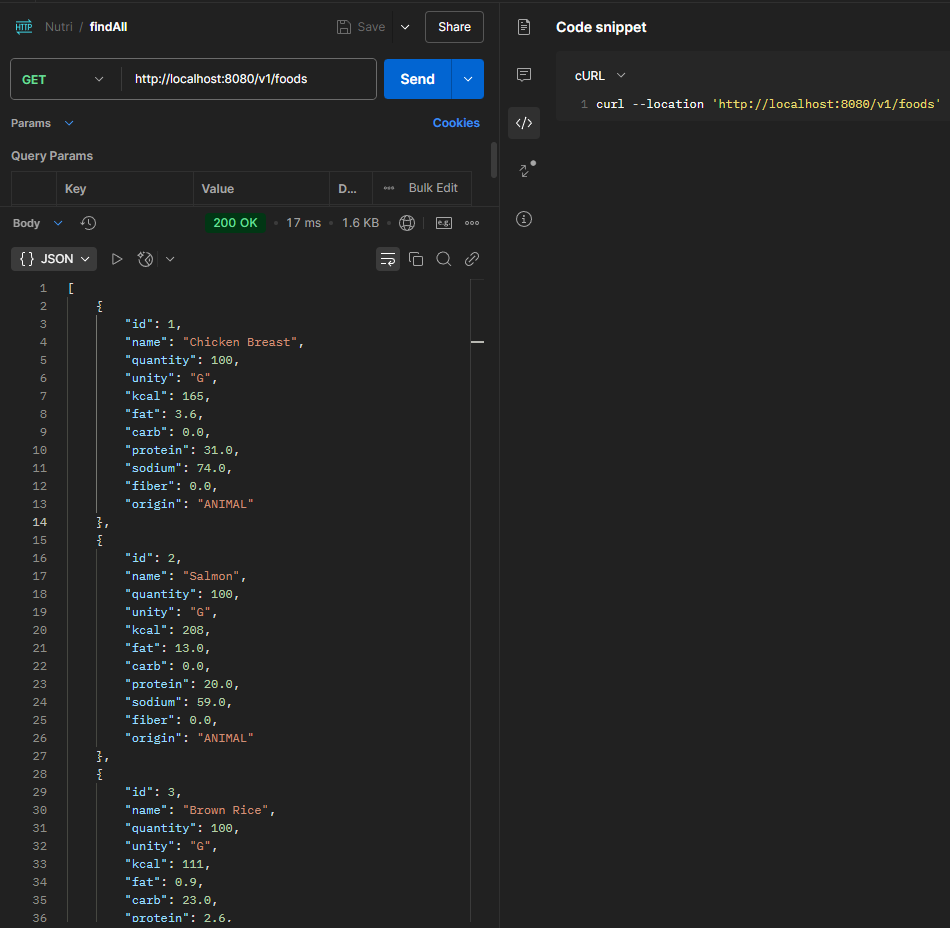
We get the following result.
If you want to see the executed queries, you can add this property to the application.properties file.
spring.jpa.show-sql=true
Query Methods
If you need methods that are not provided by default by Spring Data JPA, you can create query methods.
In the example, we’ll search by the name field. In this case, you need to define the method like this in the Repository.
@Repository
public interface FoodRepository extends JpaRepository<Food, Long> {
Optional<Food> findFirstByNameContaining(String name);
List<Food> findByNameContaining(String name);
}Optional<Food> findFirstByNameContaining(String name)
This method returns the first record (according to the default database ordering) where the name contains the provided substring (LIKE %name%).
It will return the first food item whose name contains “banana” (such as “ripe banana” or “banana cake”).
The use of Optional<Food> is to handle the case where no food is found — avoiding null.
List<Food> findByNameContaining(String name)
This method returns all food items whose name contains the given substring.
Spring Data JPA automatically creates the queries based on the method name! You don’t need to write JPQL or SQL manually for common searches.
findBy is a prefix.
There are many keywords you can use for search operations. You can find more information here:
https://docs.spring.io/spring-data/jpa/reference/jpa/query-methods.html
The following table describes the keywords supported for JPA and what a method containing that keyword translates to:
Distinct | findDistinctByLastnameAndFirstname | select distinct … where x.lastname = ?1 and x.firstname = ?2 |
And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
Is, Equals | findByFirstname,findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 (or … where x.firstname IS NULL if the argument is null) |
Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
LessThan | findByAgeLessThan | … where x.age < ?1 |
LessThanEqual | findByAgeLessThanEqual | … where x.age <= ?1 |
GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
After | findByStartDateAfter | … where x.startDate > ?1 |
Before | findByStartDateBefore | … where x.startDate < ?1 |
IsNull, Null | findByAge(Is)Null | … where x.age is null |
IsNotNull, NotNull | findByAge(Is)NotNull | … where x.age is not null |
Like | findByFirstnameLike | … where x.firstname like ?1 |
NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
Not | findByLastnameNot | … where x.lastname <> ?1 |
In | findByAgeIn(Collection<Age> ages) | … where x.age in ?1 |
NotIn | findByAgeNotIn(Collection<Age> ages) | … where x.age not in ?1 |
True | findByActiveTrue() | … where x.active = true |
False | findByActiveFalse() | … where x.active = false |
IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstname) = UPPER(?1) |
@Query
It’s also possible to write JPQL queries, especially in situations where using query methods could make the code harder to read as queries grow in complexity. Let’s look at a simple example to understand how it works.
@Query("from Food where name like %:name%")
List<Food> search(String name);@Query("from Food where name like %:name%")
%:name% is equivalent to SQL LIKE, with % used as wildcards to indicate that the name can be anywhere in the string.
This is JPQL (not raw SQL). The Food entity is used directly instead of the table name.
:name is a named parameter, which will be filled with the argument from the search(String name) method.
Conclusion
Spring Data JPA is a powerful tool that speeds up Java application development by automating much of the repetitive work related to data access. It is ideal for projects that use relational databases and follow a repository-based architecture.
If you are just getting started with Spring or want to boost your team’s productivity, Spring Data JPA is definitely worth adopting!
