What is Connection Pool?
Connection Pool is very important for improving the response time of applications. To discuss connection pool, it’s important to understand how database connections work in an application. Let’s use the example of a web application, an API.
Without Connection Pool
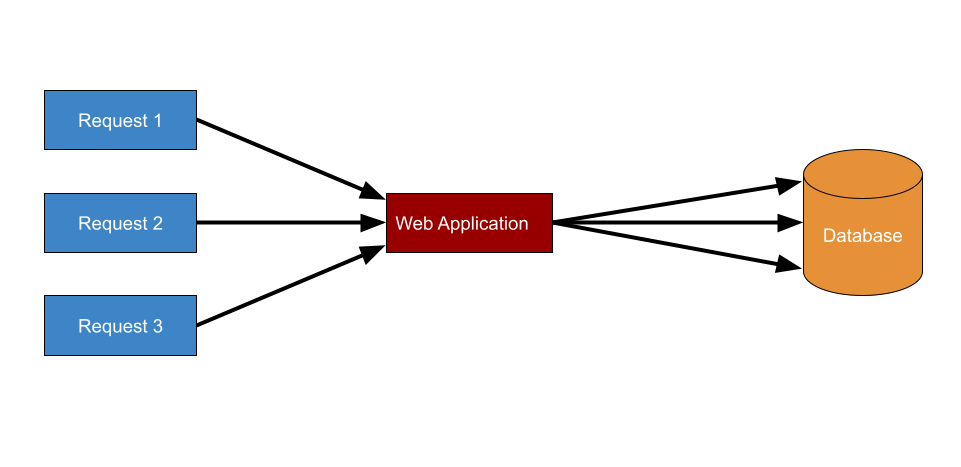
A request was made to the application to fetch some information, and in this example, that information needs to be retrieved from the database. The web application receives the user’s request, creates a new connection to the database, fetches the information from the database, and then closes the connection. This is an example without a Connection Pool.

And what if the web application receives several requests simultaneously?
This entire process will be repeated. For each request, a connection to the database is opened, the necessary operation on the database is performed, and then the connection is closed.

Connection Pool
It’s a software component that maintains a pool of database connections to allow for the reuse of these connections.
This way, we reduce the time spent on requests since there won’t be opening and closing connections as in the previous example without the connection pool.
When the application starts running, it creates connections that are available to be used.

Connections that are not being used remain in an “Idle” state.
When the application receives a request, it can use a connection that is in an “Idle” state.
In the following example, we start the application, the connections are created, and they are in an “Idle” state.

In the next example, the application receives a request.

In this way, a connection that was in an “Idle” state is used, so there is no need to open and close a new connection to the database. After completing the request, the connection returns to the “Idle” state, making it available for reuse in a new request.

Now, let’s see what happens if 5 requests are made to the web application.

In the previous example, we saw that we have 3 connections. Now, if the application receives 5 simultaneous requests, we need to consider that 3 is the minimum number of connections, but we can also define a maximum number of connections. Let’s define the following:
- Minimum connections: 3
- Maximum connections: 5
So, since the 3 connections are not enough to handle the 5 requests, two more are opened, totaling 5, which is the maximum number of connections.
If there were 6 requests?
One request would be queued, as we only have a maximum of 5 connections. After one request is completed, the next one in the queue will be able to use the connection that became “Idle“.
Let’s see step by step how it works in practice.
Requirements
To create a Spring project, I used this website: https://start.spring.io/
You need to have JDK, Maven, an IDE, JMeter (or a similar software for making simultaneous requests), and MySQL (or another database).
Project
I’ve created a very simple API with Spring that will list users from a database through an endpoint.
Dependencies
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>Properties
spring.application.name=connectionpool
spring.datasource.url=jdbc:mysql://localhost/connectionpool?createDatabaseIfNotExist=true&serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=Model class
package com.natancode.connectionpool.domain.model;
import jakarta.persistence.*;
import lombok.Data;
@Data
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String name;
}Repository
package com.natancode.connectionpool.domain;
import com.natancode.connectionpool.domain.model.User;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
}
Controller
package com.natancode.connectionpool.api;
import com.natancode.connectionpool.domain.UserRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/users")
public class UserController {
@Autowired
private UserRepository userRepository;
@GetMapping
public ResponseEntity<?> findAll() {
return ResponseEntity.ok(userRepository.findAll());
}
}Database
I created a database called connectionpool and a user table with two users.
To create the table and insert the data:
--
-- Table structure for table `user`
--
CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(45) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
--
-- Dumping data for table `user`
--
LOCK TABLES `user` WRITE;
INSERT INTO `user` VALUES (1,'Mary'),(2,'Bob');
UNLOCK TABLES;Analyzing the Connection Pool

After running the application, I checked the open connections in the database. Even without configuring a Connection Pool, we already have a Pool with several connections because Spring Data provides this by default through Hikari. We will discuss more about this later. Notice that all connections have a time of 10. I clicked refresh to update. But what does this mean?
This “time” column represents how long ago this connection was used. I’ll make one request and then click refresh right after.

This means that an open connection was reused (changed state) and released (changed state) after completion, which is why the time became 1.
At another time, I started the application to make some simultaneous requests, and we have the following result.

Configuring a connection pool with Hikari
Hikari is present in Spring Data, so we can configure the connection pool in the properties file.
I will set a minimum of 3 connections and a maximum of 5.
spring.datasource.hikari.maximum-pool-size=5
spring.datasource.hikari.minimum-idle=3As previously mentioned in the example, it will use the 3 connections, and if necessary, it will create two more connections. These additional connections can be configured to be terminated if they are not used after a certain period of time. We can do this with the following property:
spring.datasource.hikari.idle-timeout=10000The time is in milliseconds. After this period of idleness, we terminate these two connections.
After running the application, we can see that we have the 3 configured connections.

After a request, we can see that the connection was reused and then became available again. After a few seconds of availability, I clicked the refresh button, and we can observe that the other connections remained in the same state as before.

When making many requests simultaneously, two more connections were created, thus totaling the maximum of 5 that we configured.

I interrupted the requests as indicated in the image below.

After the timeout period, the two extra connections that were required are terminated because they were not needed, as explained earlier.


